



1 数据先容勾引 初中生
本次分析使用的数据来自"yc_data.csv",该文献包含了 Y Combinator(YC)创业加快器投资的公司注视信息:
文献包含多个列,如公司ID、公司称号、粗造刻画、注视刻画、YC批次、公司气象、标签、位置、国度等。
数据涵盖了从YC早期批次(如S05、W06)到最近的批次(如W24、S24)的公司。
公司气象包括Active(活跃)、Acquired(被收购)和Inactive(不活跃)等。
数据包含了好多驰名公司,如Reddit、Twitch、Scribd等。
每个公司的信息包括独创东说念主数目、独创东说念主姓名、团队范围、网站、Crunchbase贯穿和LinkedIn贯穿等。
标签列默示公司的业务边界或工夫标的,如AI、fintech、SaaS等。
location数据深刻了公司的地舆散播,主要诱骗在好意思国,但也包括其他国度的公司。
年份信息深刻了公司的创无意间,从早期到最近几年皆有。
团队范围从个位数到数千东说念主不等,反应了公司的不同发展阶段。
最近批次的公司数据深刻了现时创业趋势,如东说念主工智能、开源软件、开发者器具等边界的增长。
2 数据预照顾
最初,咱们使用 pandas 库读取 CSV 文献,并检讨数据的基本信息:
import pandas as pddf = pd.read_csv("yc_data.csv")print(df.head)
输出成果深刻,数据集包含17列,分辨为:
batch_idx: 批次索引
company_id: 公司ID
company_name: 公司称号
se情在线short_description: 粗造刻画
long_description: 注视刻画
batch: YC批次
status: 公司气象
tags: 标签
location: 位置
country: 国度
year_founded: 开垦年份
num_founders: 独创东说念主数目
founders_names: 独创东说念主姓名
team_size: 团队范围
website: 网站
cb_url: Crunchbase贯穿
linkedin_url: LinkedIn贯穿
接下来,咱们检讨数据的全体情况:
print(df.info)print(df.isnull.sum)RangeIndex: 4586 entries, 0 to 4585Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 batch_idx 4586 non-null int64 1 company_id 4586 non-null int64 2 company_name 4586 non-null object 3 short_description 4432 non-null object 4 long_description 4266 non-null object 5 batch 4586 non-null object 6 status 4586 non-null object 7 tags 4586 non-null object 8 location 4324 non-null object 9 country 4331 non-null object 10 year_founded 3563 non-null float64 11 num_founders 4586 non-null int64 12 founders_names 4586 non-null object 13 team_size 4515 non-null float64 14 website 4585 non-null object 15 cb_url 2540 non-null object 16 linkedin_url 2980 non-null object dtypes: float64(2), int64(3), object(12)memory usage: 609.2+ KBNone...website 1cb_url 2046linkedin_url 1606dtype: int64Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
从输出成果不错看出,数据集共有4586行,部分列存在缺失值,成人性爱网如short_description、long_description、location、country、year_founded等。
3 数据清洗
为了便于后续分析,咱们需要对数据进行清洗和预照顾。
# 照顾缺失值df['short_description'] = df['short_description'].fillna('No description')df['year_founded'] = df['year_founded'].fillna(df['year_founded'].median)df['team_size'] = df['team_size'].fillna(df['team_size'].median)# 创建一个新列默示公司是否得手(假定Acquired或Active气象为得手)df['is_successful'] = df['status'].isin(['Acquired', 'Active'])# 从batch列中索要年份,照顾非常情况def extract_year(batch): try: year = batch[-2:] # 索要字符串的终末两个字符 return int('20' + year) # 将年份相似为整数类型 except: return np.nandf['batch_year'] = df['batch'].apply(extract_year)# 检讨batch_year列的独一值,以检验是否还有问题print(df['batch_year'].unique)
4 探索性数据分析
当今咱们的数据照旧清算兑现,让咱们启动探索一些道理的视力:
4.1 公司气象散播
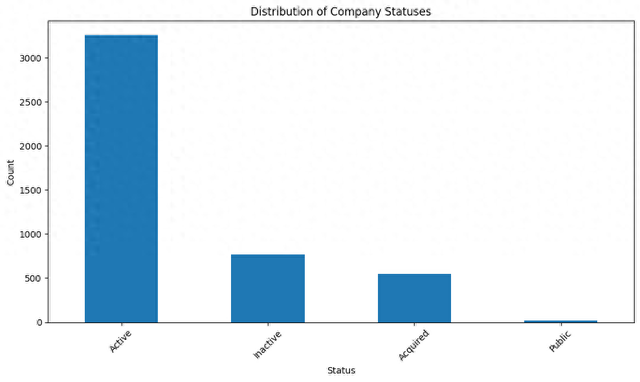
status_counts = df['status'].value_countsplt.figure(figsize=(10, 6))status_counts.plot(kind='bar')plt.title('Distribution of Company Statuses')plt.xlabel('Status')plt.ylabel('Count')plt.xticks(rotation=45)plt.tight_layoutplt.show
这段代码将生成一个柱状图,深刻不同公司气象的散播
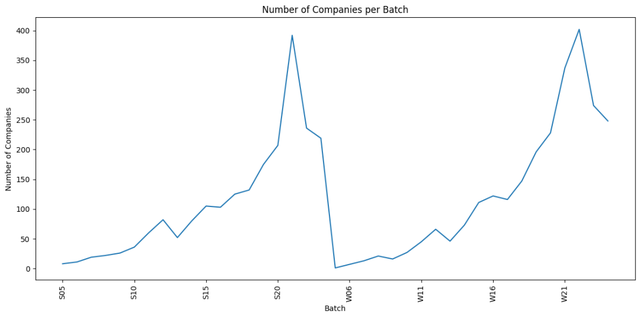
4.2 每批次公司数目的变化
这将生成一个折线图,展示每个批次的公司数目变化。
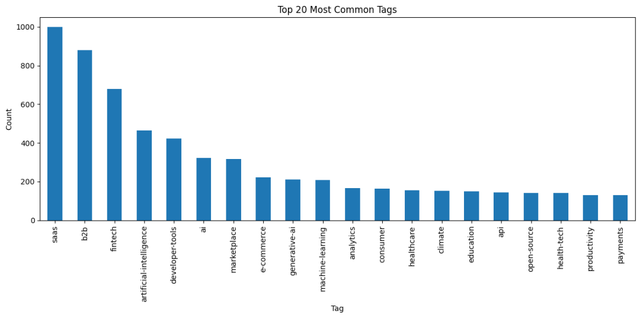
4.3 最常见的标签
这个图表将展示最常见的20个标签。
4.4 公司得手率随时候的变化
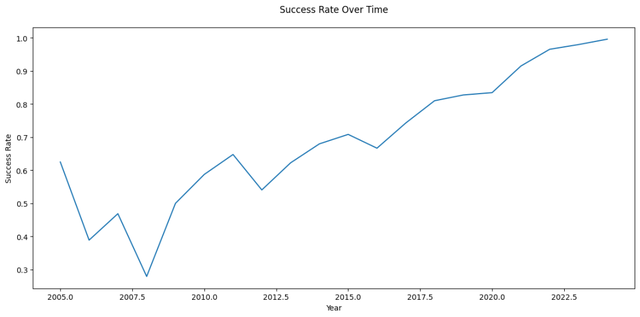
从图中不错看出,YC创业公司的得手率总体呈高涨趋势,连年来保握在较高水平。
5 假定测验
接下来,咱们使用T测验分析不同身分对得手率的影响。最初,咱们界说一个函数对给定变量进行T测验:
from scipy import statsdef perform_t_test(variable): successful_values = df[df['is_successful']][variable] unsuccessful_values = df[~df['is_successful']][variable] t_stat, p_value = stats.ttest_ind(successful_values, unsuccessful_values) print(f"Variable: {variable}") print(f"T-statistic: {t_stat}") print(f"P-value: {p_value}") print("---")Variable: year_foundedT-statistic: 4.2584208077988706P-value: 2.0999812247726262e-05---Variable: num_foundersT-statistic: 3.5994256038457904P-value: 0.0003222920811796079---Variable: team_sizeT-statistic: 0.2147248161445528P-value: 0.8299914248081315---Variable: batch_yearT-statistic: 27.695299446266723P-value: 3.067399233387115e-156---
从输出成果不错看出:
year_founded、num_founders和batch_year对得手率有权贵影响(p值小于0.05)
team_size对得手率莫得权贵影响(p值大于0.05)
6 测度模子
终末,咱们尝试使用无意丛林模子测度公司的得手率:
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, classification_reportfeatures = ['year_founded', 'num_founders', 'team_size']X = df[features]y = df['is_successful']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)rf_model = RandomForestClassifier(n_estimators=100, random_state=42)rf_model.fit(X_train, y_train)y_pred = rf_model.predict(X_test)print("Accuracy:", accuracy_score(y_test, y_pred))print("\nClassification Report:")print(classification_report(y_test, y_pred))feature_importance = pd.DataFrame({'feature': features, 'importance': rf_model.feature_importances_})feature_importance = feature_importance.sort_values('importance', ascending=False)print("\nFeature Importance:")print(feature_importance)Accuracy: 0.8540305010893247Classification Report: precision recall f1-score support False 0.61 0.51 0.56 164 True 0.90 0.93 0.91 754 accuracy 0.85 918 macro avg 0.75 0.72 0.73 918weighted avg 0.85 0.85 0.85 918Feature Importance: feature importance2 team_size 0.5623110 year_founded 0.3681181 num_founders 0.069571
从输出成果不错看出,无意丛林模子在测试集上的准确率为85.4%,阐发较好。从特征紧迫性不错看出,团队范围、开垦年份和独创东说念主数目轮番对测度成果的孝敬最大。
7 转头
通过对YC创业公司数据的分析,咱们获取以下主要论断:
YC创业公司的得手率总体呈高涨趋势,连年来保握在较高水平。
开垦年份、独创东说念主数目和批次年份对得手率有权贵影响,而团队范围对得手率莫得权贵影响。
得手公司的独创东说念主数目权贵高于不得手公司。
使用无意丛林模子不错较好地测度公司的得手率,团队范围、开垦年份和独创东说念主数目是最紧迫的测度身分。
这些发现不错为创业者和投资者提供有价值的参考和启示。
图解机器学习 - 中语版(72 张 PNG)
搭建竣工的写稿环境:器具篇(12 章)
《全网最全 Python、机器学习、AI、LLM 速查表(100 余张)》勾引 初中生
